Как составить семантическое ядро сайта
Содержание:
- Анализ конкуренции запросов для информационных сайтов
- Что такое семантическое ядро простыми словами
- Этап 2. Сбор и чистка семантического ядра в Key Collector
- ДОБРО ПОЖАЛОВАТЬ В МИР SEO
- Бесплатный парсинг запросов конкурентов
- Составление семантического ядра вручную
- СЯ и поисковые алгоритмы: как это работает в 2021 году
- Составление семантического ядра — основа интернет-маркетинга
- Как группировать запросы
- SpyWords
- Услуги по сбору семантического ядра
- Как можно собрать семантическое ядро?
Анализ конкуренции запросов для информационных сайтов
Собрав запросы и почистив их теперь нам надо проверить их конкуренцию, чтобы понимать в дальнейшем — какими запросами надо заниматься в первую очередь.
Конкуренция по количеству документов, title, главных страниц
Это все легко снимается через KEI в KeyCollector.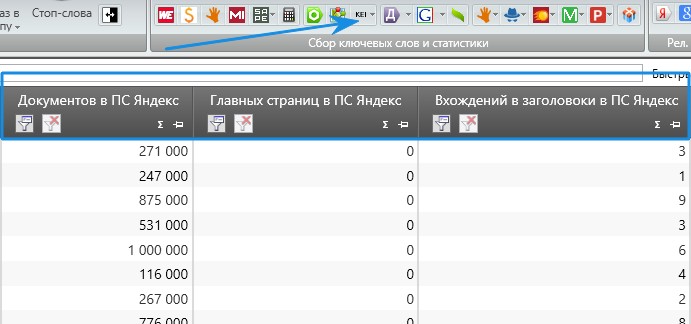 Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
Получаем данные по каждому запросу, сколько документов найдено в поисковой системе, в нашем пример в Яндексе. Сколько главных страниц в выдаче по этому запросу и вхождений запроса в заголовок.
В интернете можно встретить различные формулы расчета этих показателей, даже вроде в свежем установленном KeyCollector по стандарту встроена какая-то формула расчета KEI. Но я им не следую, потому что надо понимать что каждый из этих факторов имеет разный вес. Например, самый главный, это наличие главных страниц в выдаче, потом уже заголовки и количество документов
Навряд ли эту важность факторов, как то можно учесть в формуле и если все-таки можно то без математика не обойтись, но тогда уже эта формула не сможет вписаться в возможности KeyCollector
Конкуренция по биржам ссылок
Здесь уже интереснее. У каждой биржи свои алгоритмы расчета конкуренции и можно предположить, что они учитывают не только наличие главных страниц в выдаче, но и возраст страниц, ссылочную массу и другие параметры. В основном эти биржи конечно же рассчитаны на коммерческие запросы, но все равно более менее какие то выводы можно сделать и по информационным запросам.
Собираем данные по биржам и выводим средние показатели и уже ориентируемся по ним. Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Я обычно собираю по 2-3 биржам. Главное чтобы все запросы были собраны по одним и тем же биржам и выведено среднее число только по ним. А не так, что какие то запросы собрали одними биржами, а другие другими и вывели среднее.
Для более наглядного вида можно применить формулу KEI, которая покажет стоимость одного посетителя исходя из параметров бирж:
KEI = AverageBudget / ( AverageTraffic +0.01)
Средний бюджет по биржам делить на средний прогноз трафика по биржам, получаем стоимость одного посетителя исходя из данных бирж.
Конкуренция по мутаген
Сервис мутаген создан специально для анализа конкуренции информационных запросов. Работает с 2011 года, принцип алгоритма не разглашается, но вполне себе годно рассчитывает. Конкуренция рассчитывается по 25 баллам. Чем больше балл, тем больше конкуренция: 1-7 низкая конкуренция, 8-15 средняя, 16 и выше, высокая. Сервис платный, но в день можно чекать 10 запросов бесплатно. Тут сразу показываются просмотры по вордстату, ключи хвосты, клики в яндекс директ. В KeyCollector есть возможность массового сбора по мутаген.
В KeyCollector есть возможность массового сбора по мутаген.
Выводы: Если у вас бюджет ограничен то вы можете использовать первые два способа проверки конкуренции в совокупности, если готовы тратиться на анализ, то можно использовать только Мутаген или Оверлид.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:

Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Этап 2. Сбор и чистка семантического ядра в Key Collector
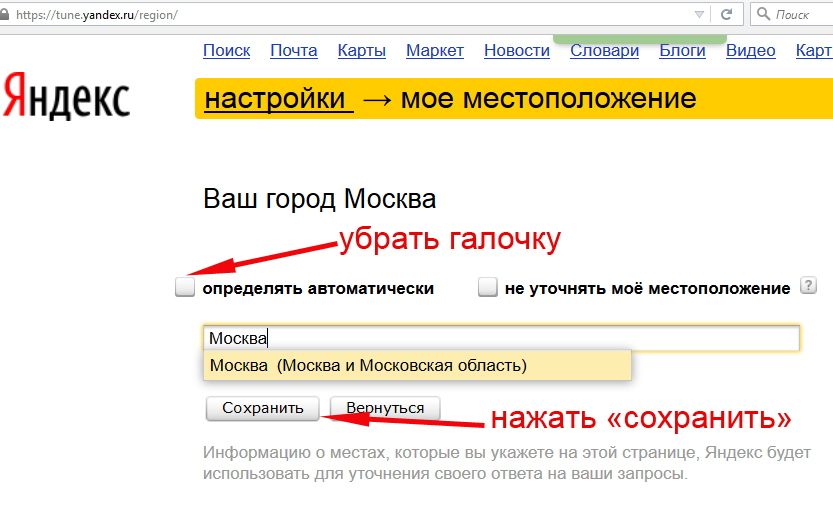
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:

Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:

Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.

Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:

ДОБРО ПОЖАЛОВАТЬ В МИР SEO
Понимание того, что такое поисковая оптимизация и как вы можете использовать ее в своих интересах. Это то, что отделит вас от конкурентов и выведет ваш сайт на новый уровень. Чаще всего пользователи либо полностью ошеломлены концепцией SEO, либо просто считают, что это обман, который не стоит денег.
Оказывается, SEO не волшебство и не уловка. Это серия проверенных и достоверных методов, которые тщательно и спланировано используются на веб-сайте для последовательного увеличения объема трафика. Неизбежным побочным эффектом увеличения трафика на сайт является повышение рейтинга в поисковых системах.
Мы хотим прояснить одну вещь: все, о чем мы будем писать в этой серии, было не только проверено несколькими другими сайтами веб-разработки, но также использовалось и реализовывалось ими. Это практический совет, используемый реальными людьми на самом деле компании.
Это наша первая статья из серии, основная цель которой – научить вас всем тонкостям поисковой оптимизации. Мы советуем вам внимательно прочесть статьи этой серии, поскольку в них содержатся полезные советы и рекомендации, которые, если их точно соблюдать, принесут вам огромный успех в онлайн-маркетинге. Эта первая статья посвящена важнейшему аспекту SEO: семантическое ядро как правильно составить.
Бесплатный парсинг запросов конкурентов
Чтобы парсить конкурентов, их надо знать. В анализе ниш я уже рассказывал, как определить своих конкурентов.
Выписываем всех ваших конкурентов, если вы еще этого не сделали. Надо брать только прям точных конкурентов. Например, у вас сайт по диабету, вам надо брать только сайты по диабету. Сайты, которые посвящены всей медицине с разделом диабета не подойдут, потому что у вас напарсятся другие разделы сайта, которые посвящены не диабету, и вы запаритесь их чистить.
Wizard.Sape
Заходите в KeyCollector во вкладку Wizard.Sape. Выбираем анализ доменов. Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.
Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.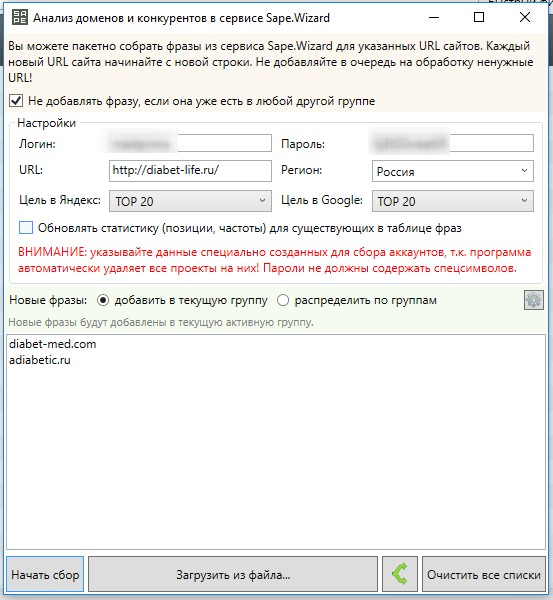 После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
Так же можно еще собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Megaindex
Заходим в KeyCollector во вкладку Megaindex. Вводим логин и пароль, указываем Москва, потому что Россию нельзя указать. Выбираем последнюю дату, раньше можно было парсить за весь период, но сейчас почему-то не работает, можно выбирать только определенную дату. Вбиваем домены конкурентов. И начинаем парсинг.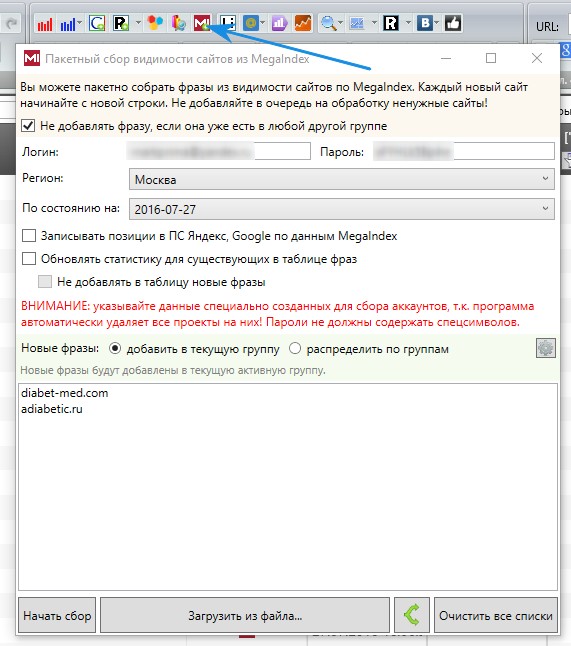
Rookee
Выбираем Rookee в Keycollector, составление семантического ядра.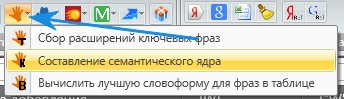 Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Можно отдельно собрать по Яндексу, потом по Гуглу. Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Top.Mail.ru
Здесь все сложнее. Необходимо перейти в рейтинг https://top.mail.ru/, и там найти ваших конкурентов с открытым счетчиком. Обычно что-то узконишевое там сложно найти, но все равно расскажу про этот способ для общего кругозора.
Вводим вашу тематику в поле поиска рейтинга. Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта.
Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта. Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id.
Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id. В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.
В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.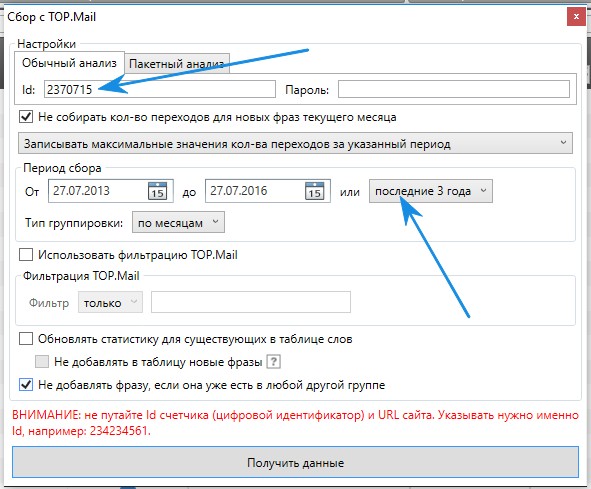 Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Так же можно спарсить глобальный рейтинг top.mail по ключевым словам, в той же самой вкладке в KeyCollector.
На этом бесплатный сбор ключевых слов у конкурентов закончен. Теперь его надо очистить и оставить только нужное.
В итоге получаем готовый список ключевых слов конкурентов, которыми можем дополнить наше ядро.
Составление семантического ядра вручную
В первую очередь, необходимо освоить ручной способ, чтобы получить базовые представления о принципах сбора ключевых слов, да и к тому же полностью автоматизировать сбор ключевых слов все равно не получится, придется вручную чистить ядро, удаляя не целевые запросы и находить маски слов.
Для ручного сбора, можно использовать всем известный яндекс вордстат, методика проста, мы находим маску слова, например семантическое ядро, и смотрим какие варианты нам выдает вордстат.
В левой колонке он покажет те запросы, которые пользователи вбивали в поиск вместе с нашей маской, их называют хвостами, в правой дополнительные, похожие варианты, с этой колонки можно также находить дополнительные целевые запросы, используя различные маски ключевых слов, необходимо собрать максимальное количество хвостов.

По умолчанию вордстат выдает ключевые фразы в широком соответствии, все фразы ниже это варианты использования основного ключевого слова, сумма показов в верхней строчке, это все показы по данному направлению во всех возможных вариантах.
Что бы получить точное (фразовое) соответствие нужно проставить кавычки, в этом случае мы получим количество запросов по точной фразе без дополнительных фраз.

Также полезный инструментом является история запросов, по которой можно определить сезонность спроса, настройка по регионам позволяет собирать ключевые фразы с нужными гео настройками.

Еще можно посмотреть популярность запросов по различным регионам.
Заносить собранные ключевые слова удобно в таблицы Exlel, с указанием широкого и точного соответствия, при этом вы можете создать определенную структуру, разбив слова на логические группы, шаблон для семантического ядра можно скачать по этой ссылке
Также собирать ключевые слова удобно через сервис мутаген, он дополнительно выдает оценку уровня конкурентности по каждому ключевому слову. Можно сделать экспорт найденных ключевых слов в формате csv, в общем довольно удобный и практичный сервис.

семантического ядра
Применяйте при поиске ключевых слов синонимы, сленг, написание на английском, продумайте все возможные варианты того как ваш товар могут искать пользователи, нужно найти как можно больше масок слов.
Поисковые подсказки
Начните набирать запрос в поисковой статье и посмотрите какие варианты вам предлагает поисковая система.

Также можно использовать для этой цели конкурентов, наиболее удобный способ получит запросы по которым продвигаются сайты конкуренты это сервис megaindex , он может оценить видимость сайта и соответственно выдает ключевые запросы по которым сайт виден в поисковых системах.
https://dramtezi.ru/
СЯ и поисковые алгоритмы: как это работает в 2021 году
Поисковики совершенствуют свои алгоритмы ранжирования, чтобы пользователи могли получать релевантную информацию. Они вводят элементы машинного обучения, позволяющие оценивать не отдельные слова, а целые смыслы. Поэтому наличие ключевых слов на веб-странице не является гарантией того, что поисковики её «заметят». Но в новых стратегиях ранжирования есть свои плюсы. В 2021 году не обязательно, чтобы ключевики полностью совпадали с поисковыми запросами. Алгоритмы учитывают синонимы и слова, которые соответствуют тематике.
- Google BERT – алгоритм с искусственным интеллектом, который работает с целыми предложениями и запросами с длинными хвостами;
- Google SMITH – появился в 2021 году, и будет работать эффективнее BERT. Если последний анализирует отдельные предложения и фразы, то новый алгоритм способен оценить смысл всего текста;
- Яндекс YATI – отечественный «трансформер» с машинным обучением способен оценить релевантность контента при отсутствии в нём конкретных поисковых запросов.
В 2021 году стала использоваться методика ранжирования пассажей – Google Passage Ranking. Поисковые роботы делят тексты на смысловые фрагменты (пассажи), а затем определяют их релевантность запросу. По интернет-запросам пользователей показываются материалы, где подсвечена только часть, в которой находится ответ на поставленный вопрос.
Составление семантического ядра — основа интернет-маркетинга
Потому что трафик бывает разным, в зависимости от вида его привлечения на ваш ресурс. Более подробно про то, каким может быть трафик можете прочитать в отдельной статье. Здесь же отметим, что люди, которые “сами” нашли вас в интернете с помощью информационных запросов — самая лояльная аудитория.
Они нанимают копирайтеров, которые за копейки пишут сотни статей, пытаясь вытолкнуть конкурентов с первых позиций в поисковой выдаче.
И новичкам кажется, что пробиться в топ-выдачу Google и Яндекс самостоятельно практически невозможно. Но это не совсем так. Если знать как правильно составить семантическое ядро самостоятельно — есть все шансы.
Понятно, что вы можете делегировать этот процесс, но только после того, как сделаете хотя бы 100 ключей своего ядра для сайта. Кстати, как правильно делегировать любую задачу вы сможете узнать из видео ниже:
Поскольку вы хотите разобраться в том, что такое семантика для сайта, дадим определение семантического ядра — это список запросов по вашей тематике, которые УЖЕ ищут пользователи в интернете.
Ну а если еще упростить, то семантика будет выглядеть ,как таблица в формате эксель. Что-то вроде этого:

Каждый ключ, в идеале, должен иметь минимум 2 важных показателя:
- Частотность. Количество вводимых запросов по данному ключу за определенный период времени.
- Конкурентность. Чем больше статей на тему данного ключа, тем выше его конкурентность и сложнее продвигаться по такому запросу.
Кстати, забыл предупредить, семантические ядра бывают двух типов, в зависимости от стратегии продвижения сайта. А именно:
- Массфолловинг. Когда делают ключевые запросы средней или низкой частотности (посещаемости). Обычно это от 5 до 100 запросов в месяц.
- Качественная работа с ключем. В этом случае подробно обрабатывается каждый ключ. Иногда работа над одним запросом может вестись около двух дней, как это было у меня.
Тут сразу возникает вопрос, какая из этих стратегий лучше? Но это не совсем корректный подход. Потому что нужно ставить вопрос по другому:
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
SpyWords
SpyWords — это онлайн-сервис, который поможет подобрать семантическое ядро на основе ключевых запросов конкурентов в рекламе и SEO-продвижении.
Инструмент поможет найти ключевые фразы, которые используют конкуренты в Яндекс или Google, и добавить их в свои рекламные кампании. Порой попадаются такие запросы, придумать которые самому тяжело.
В SpyWords можно не только скачать ключевые фразы конкурентов, но и увидеть тексты их объявлений, позиции в выдаче, дневной бюджет.
Сервис также помогает найти перспективные для продвижения продукты — те, на которые большой спрос, но без серьезной конкуренции. Об этом можно судить по стоимости клика по ключевым словам. Например, если стоимость клика довольно высокая, делаем вывод, что фразу используют много рекламодателей. Значит, есть спрос на товар и можно получить прибыль.
Если внимательнее разбирать отчеты SpyWords, можно найти ключи и нишу, где большой спрос, но мало конкурентов или дешевые клики. Следовательно, можно продвигаться там. Подход будет полезен и для контекста, и для SEO.
Сервис платный: от 3 300 рублей в месяц без учета скидок.
Услуги по сбору семантического ядра
В данной отрасли можно найти не мало организаций, которые готовы предложить вам услуги по кластеризации. Например, если вы не готовы тратить время на то, чтобы самостоятельно изучить тонкости кластеризации и выполнить ее собственными руками, то можно найти множество специалистов, готовых выполнить эту работу.
Yadrex
Yadrex — одна из первых на рынке, кто начал использовать искусственный интеллект для создания сематического ядра. Руководитель компании сам профессиональный вебмастер и специалист по SEO технологиям, поэтому он гарантирует качество работы своих сотрудников.
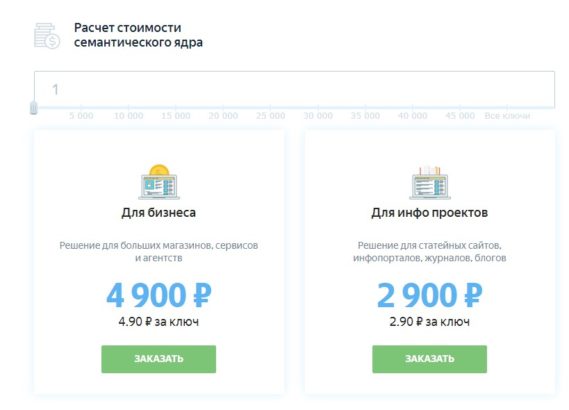
На сайте, вы можете самостоятельно рассчитать стоимость создания сематического ядра для вашей задачи.
Кроме того, вы можете позвонить по указанным телефонам, чтобы получить ответы на все интересующие вас вопросы относительно работы.
Заказывая услуги, вы получите файл, где будут указаны группы содержания ядра и его структура. Дополнительно вы получаете структуру в mindmup.
Стоимость работы варьируется в зависимости от объема, чем больше объем работы, тем дешевле стоимость одного ключа. Максимальная стоимость для информационного проекта будет 2,9 рублей за один ключ. Для продающего 4,9 рублей за ключ. При большом заказе предоставляются скидки и бонусы.
Как можно собрать семантическое ядро?
- Скопировать у конкурентов. В данном случае выбирается 2-3 сайта конкурентов и через специальные программы выкачивается информация, по каким запросам их сайты находятся в ТОП-10. Например, бесплатно получить такую информацию можно через сервис Seopult.ru. В качестве сайтов конкурентов можно выбирать самые популярные сайты в тематике или сайты компаний, ассортимент которых максимально близок вашему проекту.Плюсы способа: экономия времени на создании семантического ядра, относительная простота и бесплатность.Минусы способа: большое количество «мусорных» запросов, полученные данные потребуется фильтровать и дополнительно обрабатывать, есть риск копирования ошибок конкурентов. В семантику не попадут запросы, которые по каким-то причинам конкуренты не выбрали или не нашли.
- Продвигать запросы, близкие к ТОПу. Продвижение сайта по запросам, позиции по которым близки к ТОПу. Данный способ подходит только для старых сайтов, которые ранее продвигались. Через системы из п.1 собирается информация, по каким запросам проект находится в ТОП-30 и данные запросы включаются в семантическое ядро.Плюсы способа: экономия времени и бюджета заказчика. Более быстрая отдача от продвижения.Минусы способа: данный подход позволяет собрать минимальное количество запросов. В дальнейшем семантическое ядро необходимо расширять. Нет гарантий, что все запросы, которые будут получены – эффективны для бизнеса клиента.
- Создать семантическое ядро «с нуля». Семантика формируется, исходя из глубокого анализа запросов, по которым могут искать продвигаемые товары, услуги или информацию.Плюсы способа: сбор максимального количества запросов для максимально эффективного продвижения.Минусы способа: долго и дорого.